Fitting probability distributions#
Fitting probability distributions to data is an important task in any discipline of science and engineering, as these distributions can be used to derive quantitative statements about risks and frequencies of uncertain properties. Probabilistic tools can be applied to model this uncertainty. In this workshop, you will work with a dataset of your choosing estimate a distribution and evaluate the quality of your fit.
The goal of this project is:
Choose a reasonable distribution function for your chosen dataset, analyzing the statistics of the observations.
Fit the chosen distributions by moments.
Assess the fit computing probabilities analytically.
Assess the fit using goodness of fit techniques and computer code.
The project will be divided into 3 parts: 1) data analysis, 2) pen and paper stuff (math practice!), and 3) programming.
# Let us load some required libraries
import numpy as np # For math
import matplotlib.pyplot as plt # For plotting
from matplotlib.gridspec import GridSpec # For plotting
import pandas as pd # For file-wrangling
from scipy import stats # For math
# This is just cosmetic - it updates the font size for our plots
plt.rcParams.update({'font.size': 14})
Please choose one of the following datasets:
Observations of the compressive strength of concrete. The compressive strength of concrete is key for the safety of infrastructures and buildings. However, a lot of boundary conditions influence the final resistance of the concrete, such the cement content, the environmental temperature or the age of the concrete. (You can read more about the dataset here)
ERA5 predictions of the hourly temperature at 2m height during the summer months (June, July, August) from 2005 to 2025. ERA5 predictions are re-analysis data, which are observation-corrected weather model predictions. Like most climate data, they depend on chaotic global weather dynamics, which precise long-term predictions difficult. (The data set is extracted from here.)
import os
from urllib.request import urlretrieve
# This function searches for the data files we require, and downloads them from a server if unsuccessful
def findfile(fname):
if not os.path.isfile(fname):
print(f"Downloading {fname}...")
urlretrieve('http://files.mude.citg.tudelft.nl/'+fname, fname)
# We download two datasets for concrete and temperature data
findfile('dataset_concrete.csv')
findfile('dataset_temperature.csv')
Downloading dataset_concrete.csv...
Downloading dataset_temperature.csv...
# Please choose one of the datasets below
viable_datasets = ['concrete','temperature']
dataset = 'concrete' # Choose one dataset from the list above
# Automated check to see if the user selection is viable
assert dataset in viable_datasets, "Dataset must be in {}. You have selected {}.".format(str(viable_datasets),dataset)
# Load the data
data = np.genfromtxt('dataset_{}.csv'.format(dataset), skip_header=1)
# Set the axis labels for the dataset
if dataset == "concrete":
label = "Concrete compressive strength [MPa]"
number_bins = 10 # Depending on the number of data points, we may want to use different bin numbers for the histogram
elif dataset == "temperature":
label = "Summer air temperature in Delft [°C]"
number_bins = 20 # Depending on the number of data points, we may want to use different bin numbers for the histogram
Now, let us clean and plot the data.
# Clean the data by removing all NaN entries
data = data[~np.isnan(data)]
# Create a figure that shows the time series
plt.figure(figsize=(10, 6))
# GridSpec allows you to specify the size and relative positions of subplots, which can be very useful for plotting
gs = GridSpec(
nrows = 1, # We want one row
ncols = 2, # We want two columns
width_ratios = [1,0.2]) # The second column should only be 20% as wide as the first column
# In the first subplot, we plot the raw data series
plt.subplot(gs[0,0])
plt.plot(data,'ok')
plt.xlabel("observation number")
plt.ylabel(label)
ylims = plt.gca().get_ylim()
# In the second subplot, we plot the histogram
plt.subplot(gs[0,1])
plt.hist(data, orientation='horizontal', color='lightblue', rwidth=0.9, bins = number_bins)
plt.xlabel("frequency")
plt.gca().set_ylim(ylims)
(-1.6815630164000002, 86.6125956484)
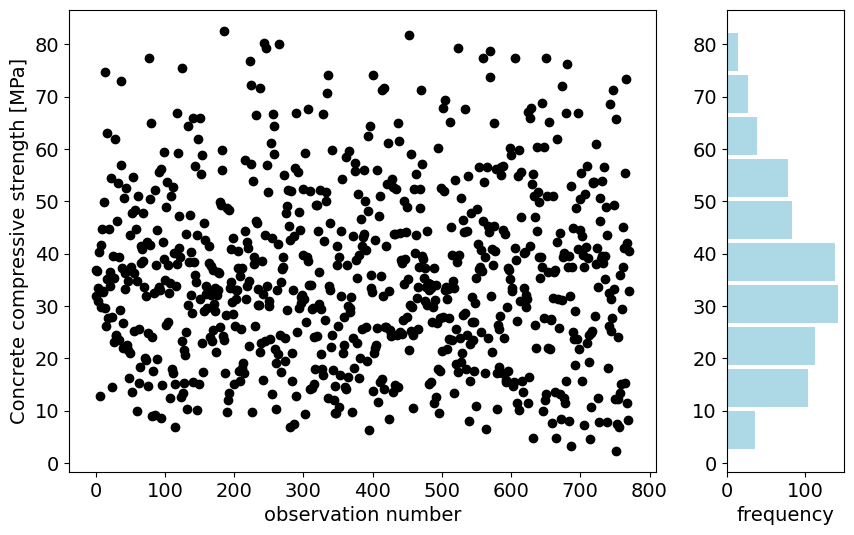
In the figure above, you can see all the observations of your chosen dataset. You can see that there is no clear pattern in the observations. Let’s see how the statistics look like!
# Statistics
df_describe = pd.DataFrame(data)
df_describe.describe()
| 0 | |
|---|---|
| count | 772.000000 |
| mean | 35.724196 |
| std | 16.797389 |
| min | 2.331808 |
| 25% | 23.677591 |
| 50% | 33.870853 |
| 75% | 46.232813 |
| max | 82.599225 |
Task 1.1: Using ONLY the statistics calculated in the previous lines:
Your answer here.
Solution for the concrete dataset:
Appropriate distribution: Gumbel.
Explanation: Uniform and Gaussian distributions are symmetric so they are not appropriate to model the observations. We can see the asymmetry by computing the difference between the minimum value and the P50% and between the maximum value and P50%:
\(d_{min, 50} = 33.87-2.33 = 31.54\)
\(d_{50, max} = 82.60 - 33.87 = 48.72\)
Since the \(d_{min, 50} < d_{50, max}\), the Gumbel distribution is right-tailed.
Solution for the temperature dataset:
Appropriate distribution: Gumbel.
Explanation: Uniform and Gaussian distributions are symmetric so they are not appropriate to model the observations. We can see the asymmetry by computing the difference between the minimum value and the P50% and between the maximum value and P50%:
\(d_{min, 50} = 17.0-6.5 = 11.5\)
\(d_{50, max} = 36.7 - 17.0 = 19.3\)
Since the \(d_{min, 50} < d_{50, max}\), the Gumbel distribution is right-tailed.
Part 2: Use pen and paper!#
Once you have selected the appropriate distribution, you are going to fit it by moments manually and check the fit by computing some probabilities analytically. Remember that you have all the information you need in the textbook. Do not use any computer code for this section, you have to do in with pen and paper. You can use the notebook as a calculator.
Task 2.1: Fit the selected distribution by moments.
Your answer here.
Solution for the concrete dataset:
Fitting by moments a distribution implies equating the moments of the observations to those of the parametric distribution. Applying then the expressions of the mean and variance of the Gumbel distribution we obtain:
\( \mathbb{V}ar(X) = \cfrac{\pi^2}{6} \beta^2 \to \beta = \sqrt{\cfrac{6\mathbb{V}ar(X)}{\pi^2}}=\sqrt{\cfrac{6 \cdot 16.797^2}{\pi^2}}= 13.097 \)
\( \mathbb{E}(X) = \mu + \gamma \beta \to \mu = \mathbb{E}(X) - \gamma \beta = 35.724 - 0.577 \cdot 13.097 = 28.167 \)
where we recall that \(\gamma \approx 0.577\) is the Euler-Mascheroni constant.
Solution for the temperature dataset:
Fitting by moments a distribution implies equating the moments of the observations to those of the parametric distribution. Applying then the expressions of the mean and variance of the Gumbel distribution we obtain:
\( \mathbb{V}ar(X) = \cfrac{\pi^2}{6} \beta^2 \to \beta = \sqrt{\cfrac{6\mathbb{V}ar(X)}{\pi^2}}=\sqrt{\cfrac{6 \cdot 3.733^2}{\pi^2}}= 2.911 \)
\( \mathbb{E}(X) = \mu + \gamma \beta \to \mu = \mathbb{E}(X) - \gamma \beta = 17.407 - 0.577 \cdot 2.911 = 15.727 \)
where we recall that \(\gamma \approx 0.577\) is the Euler-Mascheroni constant.
We can now check the fit by computing manually some probabilities from the fitted distribution and comparing them with the empirical ones.
Task 2.2: Check the fit of the distribution:
Tip: To compute the minimum value and maximum value for the predicted quantiles, you can use the expected minimum and maximum values for a dataset of the same size of your observations. Recall how the computed the non-exceedance probability of the first and last rank samples in an empirical CDF.
Minimum value |
P25% |
P50% |
P75% |
Maximum value |
|
|---|---|---|---|---|---|
Non-exceedance probability [\(-\)] |
0.25 |
0.50 |
0.75 |
||
Empirical quantiles |
|||||
Predicted quantiles |
Solution for the concrete dataset:
Minimum value |
P25% |
P50% |
P75% |
Maximum value |
|
|---|---|---|---|---|---|
Non-exceedance probability [\(-\)] |
1/(772+1) |
0.25 |
0.5 |
0.75 |
772/(772+1) |
Empirical quantiles [MPa] |
2.332 |
23.678 |
33.871 |
46.232 |
82.599 |
Predicted quantiles [MPa] |
3.353 |
23.889 |
32.967 |
44.485 |
115.257 |
Note: you can compute the values of the random variable using the inverse of the CDF of the Gumbel distribution:
\( F(x) = e^{\normalsize -e^{\normalsize-\cfrac{x-\mu}{\beta}}} \to x = -\beta \ln\left(-\ln F\left(x\right)\right) + \mu \)
Compare and assess:
The values close to the central moments (P25%, P50% and P75%) are well fitted. Regarding the left tail, the fit is reasonable, since the predicted value for the minimum observation is the same order of magnitude although not accurate. Finally, the right tail is not properly fitted since the estimation for the maximum observation is far from the actual value.
Solution for the temperature dataset:
Minimum value |
P25% |
P50% |
P75% |
Maximum value |
|
|---|---|---|---|---|---|
Non-exceedance probability [\(-\)] |
1/(44160+1) |
0.25 |
0.5 |
0.75 |
44160/(44160+1) |
Empirical quantiles [°C] |
6.5 |
14.9 |
17.0 |
19.5 |
36.70 |
Predicted quantiles [°C] |
8.8 |
14.8 |
16.8 |
19.4 |
46.9 |
Note: you can compute the values of the random variable using the inverse of the CDF of the Gumbel distribution:
\( F(x) = e^{\normalsize -e^{\normalsize-\cfrac{x-\mu}{\beta}}} \to x = -\beta \ln\left(-\ln F\left(x\right)\right) + \mu \)
Compare and assess:
The values close to the central moments (P25%, P50% and P75%) are well fitted. Regarding the left tail, the fit is reasonable, since the predicted value for the minimum observation is the same order of magnitude although not accurate. Finally, the right tail is not properly fitted since the estimation for the maximum observation is far from the actual value.
Part 3: Let’s do it with Python!#
Now, let’s assess the performance using further goodness of fit metrics and see whether they are consistent with the previously done analysis. Note that you have the pseudo-code for the empirical CDF in the reader.
Task 3.1: Prepare a function to compute the empirical cumulative distribution function.
def ecdf(observations):
"""Write a function that returns [non_exceedance_probabilities, sorted_values]."""
sorted_values = np.sort(observations)
n = sorted_values.size
non_exceedance_probabilities = np.arange(1, n+1) / (n + 1)
return [non_exceedance_probabilities, sorted_values]
Task 3.2: Transform the parameters of the selected distribution you fitted by moments to loc-scale-shape.
Hint: the distributions are listed in our online textbook, but it is also critical to make sure that the formulation in the book is identical to that of the Python package we are using. You can do this by finding the page of the relevant distribution in the Scipy.stats documentation.
Your answer here.
Solution for the concrete dataset:
The Gumbel distribution is already parameterized in terms of loc-scale-shape. You don’t need to do anything!
Solution for the temperature dataset:
The Gumbel distribution is already parameterized in terms of loc-scale-shape. You don’t need to do anything!
Task 3.3: Assess the goodness of fit of the distribution you fitted using the method of moments by:
Hint: Use Scipy’s built in functions (watch out for the definition of the parameters!).
# SOLUTION for the CONCRETE dataset
if dataset == "concrete":
loc = 28.167
scale = 13.097
distribution = stats.gumbel_r.pdf(np.sort(data), loc, scale)
distribution_label = 'Gumbel PDF'
# SOLUTION for the TEMPERATURE dataset
elif dataset == "temperature":
loc = 15.727
scale = 2.911
distribution = stats.gumbel_r.pdf(np.sort(data), loc, scale)
distribution_label = 'Gumbel PDF'
fig, axes = plt.subplots(1, 1, figsize=(10, 5))
axes.hist(data,
edgecolor='k', linewidth=0.2, color='cornflowerblue',
label='Empirical PDF', density = True, bins = number_bins)
axes.plot(np.sort(data), distribution,
'k', linewidth=2, label=distribution_label)
axes.set_xlabel(label)
axes.set_title('PDF', fontsize=18)
axes.legend()
<matplotlib.legend.Legend at 0x7f2b72686a20>
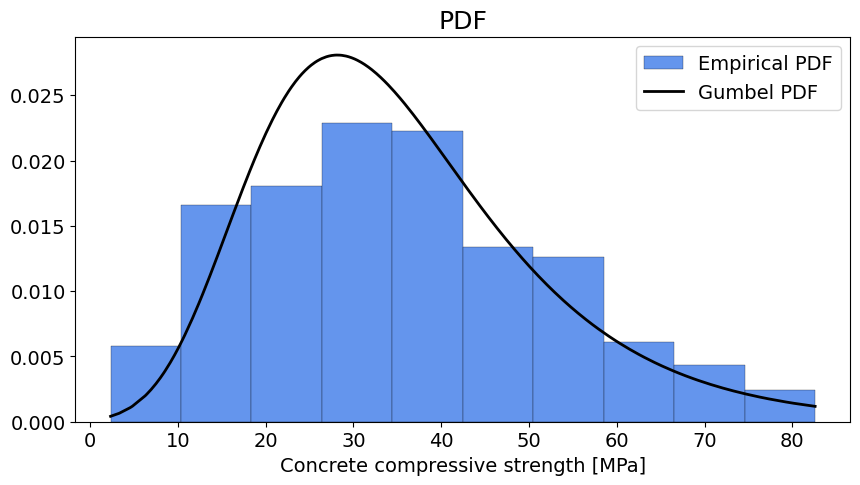
# SOLUTION for the CONCRETE dataset
if dataset == "concrete":
loc = 28.167
scale = 13.097
non_exceedance_probabilities, sorted_values = ecdf(data)
cdf = stats.gumbel_r.cdf(sorted_values, loc, scale)
distribution_label = 'Gumbel PDF'
# SOLUTION for the TEMPERATURE dataset
elif dataset == "temperature":
loc = 15.727
scale = 2.911
non_exceedance_probabilities, sorted_values = ecdf(data)
cdf = stats.gumbel_r.cdf(sorted_values, loc, scale)
distribution_label = 'Gumbel PDF'
# SOLUTION
fig, axes = plt.subplots(1, 1, figsize=(10, 5))
axes.step(sorted_values, 1-non_exceedance_probabilities,
color='k', label='Empirical PDF')
axes.plot(sorted_values, 1-cdf,
color='cornflowerblue', label=distribution_label)
axes.set_xlabel(label)
axes.set_ylabel('${P[X > x]}$')
axes.set_title('Exceedance probability in log-scale', fontsize=18)
axes.set_yscale('log')
axes.legend()
axes.grid()
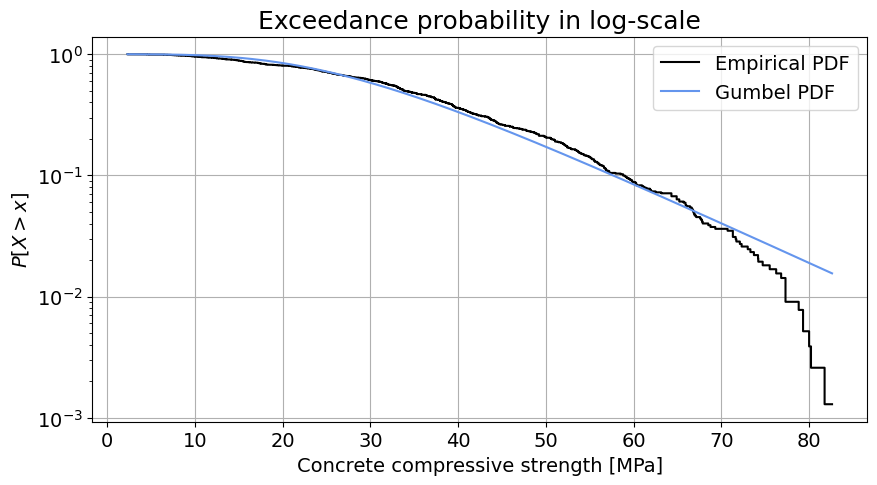
# SOLUTION for the CONCRETE dataset
if dataset == "concrete":
loc = 28.167
scale = 13.097
non_exceedance_probabilities, sorted_values = ecdf(data)
inverse_cdf = stats.gumbel_r.ppf(non_exceedance_probabilities, loc, scale)
distribution_label = 'Gumbel PDF'
# SOLUTION for the TEMPERATURE dataset
elif dataset == "temperature":
loc = 15.727
scale = 2.911
non_exceedance_probabilities, sorted_values = ecdf(data)
inverse_cdf = stats.gumbel_r.ppf(non_exceedance_probabilities, loc, scale)
distribution_label = 'Gumbel PDF'
fig, axes = plt.subplots(1, 1, figsize=(5, 5))
axes.scatter(sorted_values, inverse_cdf,
color='cornflowerblue', label=distribution_label)
axes.set_xlabel('Observed '+label)
axes.set_ylabel('Estimated '+label)
axes.set_title('QQplot', fontsize=18)
xlims = axes.get_xlim()
ylims = axes.get_ylim()
axes.plot([np.min([xlims[0],ylims[0]]), np.max([xlims[1],ylims[1]])], [np.min([xlims[0],ylims[0]]), np.max([xlims[1],ylims[1]])], 'k')
axes.grid()
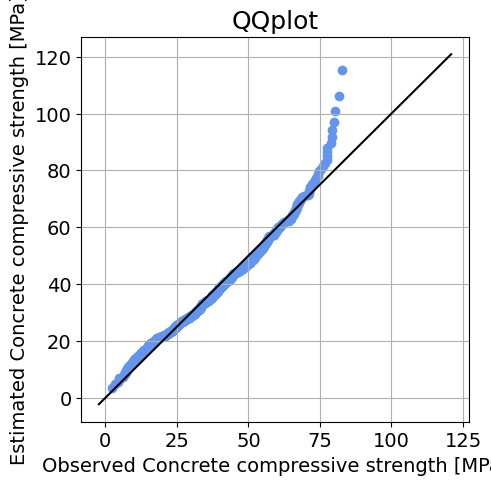
Solution for the concrete dataset:
Comparing the PDF: The fitted distribution approximately follows the bell shape of the observations with a right tail, so Gumbel distribution seems an appropriate choice considering the shape of the PDF.
Logscale plot: This technique allows to visually assess the fitting of the parametric distribution to the tail of the empirical distribution. We can see that the tail of the empirical distribution is not well fitted. The estimated Gumbel distribution provides higher estimates of the random variable than the actual values. If we are concerned about low compressive strength, we should be wary that the fitted distribution may be overly optimistic about the frequency of extraordinarily high compressive strength values.
QQplot: Again, we can see that the distribution performs well around the central moments and left tail, but the right tail is not properly fitted.
The conclusions reached with this analysis are similar to those obtained in the analytical part (pen and paper), since the techniques are equivalent. We can make use of the computer power to obtain more robust conclusions.
Solution for the temperature dataset:
Comparing the PDF: The fitted distribution approximately follows the bell shape of the observations with a right tail, so Gumbel distribution seems an appropriate choice considering the shape of the PDF.
Logscale plot: This technique allows to visually assess the fitting of the parametric distribution to the tail of the empirical distribution. We can see that the tail of the empirical distribution is not well fitted. Howvever, note that the y axis is logarithmic, The Gumbel distribution provides higher estimates of the random variable than the actual values in the right tail. It is difficult to discern the performance of the left tail in this figure. Here, if we consider high temperature extremes as dangerous, the estimated distribution is on the safe side: compared to the observations, it predicts a higher probability of exceeding any given temperature in the right tail.
QQplot: Again, we can see that the distribution performs well around the central moments, but the left and right tails are not properly fitted. Specifically, the estimated distribution predicts higher temperatures in the extremes than the observed distribution.
The conclusions reached with this analysis are similar to those obtained in the analytical part (pen and paper), since the techniques are equivalent. We can make use of the computer power to obtain more robust conclusions.
By Max Ramgraber, Patricia Mares Nasarre and Robert Lanzafame, Delft University of Technology. CC BY 4.0, more info on the Credits page of Workbook.