Mean and Variance Propagation#
Application: Sewer Pipe Flow Velocity#
We will apply Manning’s formula for the flow velocity \(V\) in a sewer:
where \(R\) is the hydraulic radius of the sewer pipe (\(m\)), \(S\) the slope of the pipe (\(m/m\)), and \(n\) is the coefficient of roughness [\(-\)].
Both \(R\) and \(S\) are random variables, as it is known that sewer pipes are susceptible to deformations; \(n\) is assumed to be deterministic and in our case \(n=0.013\) \(s/m^{1/3}\). The sewer pipe considered here has mean values \(\mu_R\), \(\mu_S\), and standard deviations \(\sigma_R\) and \(\sigma_S\); \(R\) and \(S\) are independent.
We are now interested in the mean flow velocity in the sewer as well as the uncertainty expressed by the standard deviation. This is important for the design of the sewer system.
Disclaimer: the dimensions of the pipe come from a real case study, but some aspects of the exercise are…less realistic.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.stats import probplot
import ipywidgets as widgets
from ipywidgets import interact
plt.rcParams.update({'font.size': 14})
Theory: Propagation laws for a function of 2 random variables#
We are interested in the mean and variance of \(X\), which is a function of 2 random variables: \(X=q(Y_1,Y_2)\). The mean and covariance matrix of \(Y\) are assumed to be known:
The second-order Taylor series approximation of the mean \(\mu_X\) is then given by:
In most practical situations, the second-order approximation suffices.
For the variance \(\sigma_X^2\) it is common to use only the first-order approximation, given by:
Part 1: Apply the Propagation Laws#
We are interested to know how the uncertainty in \(R\) and \(S\) propagates into the uncertainty of the flow velocity \(V\). We will first do this analytically and then implement it in code.
Task 1.1:
Use the Taylor series approximation to find the expression for \(\mu_V\) and \(\sigma_V\) as function of \(\mu_R\), \(\sigma_R\), \(\mu_S\), \(\sigma_S\).
Task 1.2:
Complete the function below, such that moments_of_taylor_approximation will compute the approximated \(\mu_V\) and \(\sigma_V\), as found in the previous Task.
def moments_of_taylor_approximation(mu_R, mu_S, sigma_R, sigma_S,n):
"""Compute Taylor series approximation of mean and std of V.
Take moments and function parameters as inputs (type float).
Returns mean and standard deviation of V (type float).
"""
constant = 1/n
dVdR = (2/3)*constant*(mu_R**(-1/3))*(mu_S**(1/2))
dVdS = (1/2)*constant*(mu_R**(2/3))*(mu_S**(-1/2))
dVdR_2 = (-2/9)*constant*(mu_R**(-4/3))*(mu_S**(1/2))
dVdS_2 = (-1/4)*constant*(mu_R**(2/3))*(mu_S**(-3/2))
mu_V_0 = constant*(mu_R**(2/3))*(mu_S**(1/2))
mu_V = mu_V_0 + 0.5*dVdR_2*sigma_R**2 + 0.5*dVdS_2*sigma_S**2
var_V = (dVdR**2)*sigma_R**2 + (dVdS**2)*sigma_S**2
sigma_V = np.sqrt(var_V)
return mu_V, sigma_V
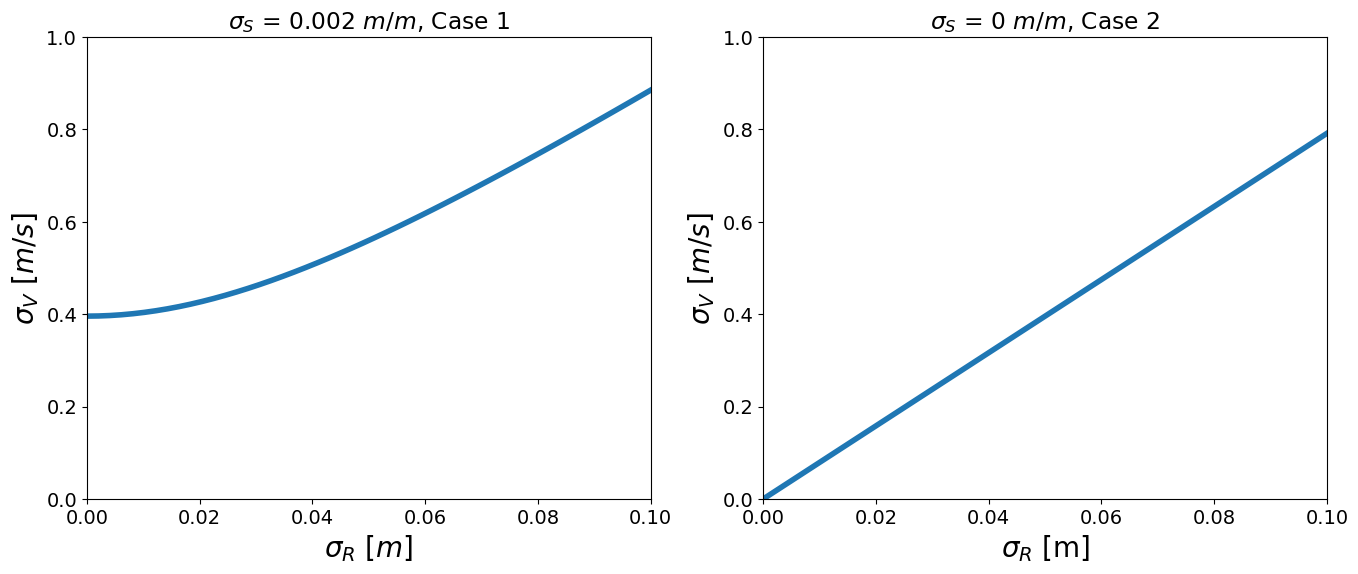
Now we use the Taylor approximation and make two plots of \(\sigma_V\) as a function of \(\sigma_R\) for the following cases:
\(\sigma_S\) = 0.002 \(m/m\)
\(\sigma_S\) = 0 \(m/m\) (i.e., slope is deterministic, not susceptible to deformation)
We will use \(\mu_R = 0.5 m\) and \(\mu_S = 0.015 m/m\), and vary \(\sigma_R\) from 0 to 0.1 \(m\).
n = 0.013
mu_R = 0.5
mu_S = 0.015
sigma_R = np.linspace(0.0, 0.1, 50)
# case 1 for sigma_S
sigma_S_1 = 0.002
mu_V_1, sigma_V_1 = moments_of_taylor_approximation(mu_R, mu_S, sigma_R, sigma_S_1, n)
# case 2 for sigma_S
sigma_S_2 = 0
mu_V_2, sigma_V_2 = moments_of_taylor_approximation(mu_R, mu_S, sigma_R, sigma_S_2, n)
fig, ax = plt.subplots(1, 2, figsize = (16, 6))
# left side plot for case 1
ax[0].plot(sigma_R, sigma_V_1, linewidth=4)
ax[0].set_ylabel(r'$\sigma_V$ [$m/s$]', size = 20)
ax[0].set_xlabel(r'$\sigma_R$ [$m$]', size = 20)
ax[0].set_title(r'$\sigma_S$ = ' + f'{sigma_S_1} $m/m$, Case 1')
ax[0].set_xlim(0, 0.1)
ax[0].set_ylim(0, 1)
# right side plot for case 2
ax[1].plot(sigma_R, sigma_V_2, linewidth=4)
ax[1].set_ylabel(r'$\sigma_V$ [$m/s$]', size = 20)
ax[1].set_xlabel(r'$\sigma_R$ [m]', size = 20)
ax[1].set_title(r'$\sigma_S$ = ' + f'{sigma_S_2} $m/m$, Case 2')
ax[1].set_xlim(0, 0.1)
ax[1].set_ylim(0, 1)
plt.show()
Task 1.3:
Interpret the figures above, specifically looking at differences between Case 1 and Case 2. Look at the equations you derived to understand why for Case 1 we get a non-linear relation, and for Case 2 a linear one.
Solution 1.3:
The standard deviation of \(V\) is a non-linear function of \(\sigma_R\) and \(\sigma_S\) - the left figure shows how \(\sigma_V\) increases as function of \(\sigma_R\) for a given value \(\sigma_S\). If \(\sigma_S\) is zero, there is no uncertainty in the slope of the pipe, and the standard deviation of \(V\) becomes a linear function of \(\sigma_R\) (right figure). The uncertainty of \(V\) is smaller now, since it only depends on the uncertainty in \(R\).
Part 2: Simulation-Based Propagation#
We will use again the following values:
\(\mu_R = 0.5\) m
\(\mu_S = 0.015\) m/m
\(\sigma_R=0.05\) m
\(\sigma_S=0.002\) m/m
It is assumed that \(R\) and \(S\) are independent and normally distributed random variables. We will generate at least 10,000 simulated realizations each of \(R\) and \(S\) using a random number generator, and then use these to calculate the corresponding sample values of \(V\) to find the moments of that sample.
A Note on “Sampling”#
We will use Monte Carlo Simulation to create an empirical “sample” of the random values of our function of random variables, \(V\) (the output). This is a commonly used approach widely used in science and engineering applications. It is a numerical way of computing the distribution of a function that is useful when analytic approaches are not possible (for example, when the input distributions are non-Normal or the function is non-linear). For our purposes today, Monte Carlo Simulation is quite simple and involves the following steps:
Define a function of random variables and the distributions of its input parameters.
Create a random sample of each input parameter according to the specified distribution.
Create a random sample of the output variable by computing the function for every set of input samples.
Evaluate the resulting distribution of the output.
A few key points to recognize are:
As the sample size increases, the resulting distribution becomes more accurate.
This is a way to get the (approximately) “true” distribution of a function of random variables.
Accuracy is relative to the propagation of uncertainty through the function based on the assumed distributions of the input random variables. In other words, MCS can’t help you if your function and distributions are poor representations of reality!
Task 2.1:
Complete the functions function_of_random_variables and get_samples below to define the function of random variables and then:
Generate a sample of the output from this function, assuming the inputs are also random variables with the Normal distribution.
Find the moments of the samples.
def function_of_random_variables(R, S):
V = 1/n*R**(2/3)*S**(1/2)
return V
def get_samples(N, sigma_R, mu_R=0.5, mu_S=0.015, sigma_S=0.002, n=0.013):
"""Generate random samples for V from R and S."""
R = np.random.normal(mu_R, sigma_R, N)
S = np.random.normal(mu_S, sigma_S, N)
V = function_of_random_variables(R, S)
return V
V_samples = get_samples(10000, 0.05)
mu_V_samples = V_samples.mean()
sigma_V_samples = V_samples.std()
print('Moments of the SAMPLES:')
print(f' {mu_V_samples:.4f} m/s is the mean, and')
print(f' {sigma_V_samples:.4f} m/s is the std dev.')
mu_V_taylor, sigma_V_taylor = moments_of_taylor_approximation(mu_R, mu_S, 0.05, 0.002, n)
print('\nMoments of the TAYLOR SERIES APPROXIMATION:')
print(f' {mu_V_taylor:.4f} m/s is the mean, and')
print(f' {sigma_V_taylor:.4f} m/s is the std dev.')
Moments of the SAMPLES:
5.9090 m/s is the mean, and
0.5624 m/s is the std dev.
Moments of the TAYLOR SERIES APPROXIMATION:
5.9151 m/s is the mean, and
0.5596 m/s is the std dev.
Task 2.2:
Are the results similar for the linearized and simulated values? Describe the difference quantitatively. Check your result also for the range of values of \(\sigma_R\) from 0.01 to 0.10; are they consistent?
Solution 2.2:
The estimated moments are both generally within 0.01 m of the result from the simulation when \(\sigma_R = 0.05\) m. When \(\sigma_R\) changes, the mean \(\mu_V\), is affected much less than the standard deviation, \(\sigma_V\). When \(\sigma_R = 0.1\) m, Taylor approximation is higher by 0.15 m; when \(\sigma_R = 0.1\) m, the Taylor approximation is lower by 0.30 m.
Task 2.3:
Run the cell with the sampling algorithm above repeatedly and look at the values printed in the cell output. Which values change? Which values do not change? Explain why, in each case.
Solution 2.2:
The moments calculated from the sample change because they are computed from random values sampled from the distribution; thus every time we run the code the samples are slightly different. The sample size seems large enough to give accurate results for our purposes, since the values don’t change significantly (i.e, less than 1%; less than the difference between the two estimates of the moments). The moments calculated from the Taylor series approximation remain fixed, as they are based on moments of the input variables, not randomly generated samples.
Part 3: Validating the Moments with a Distribution#
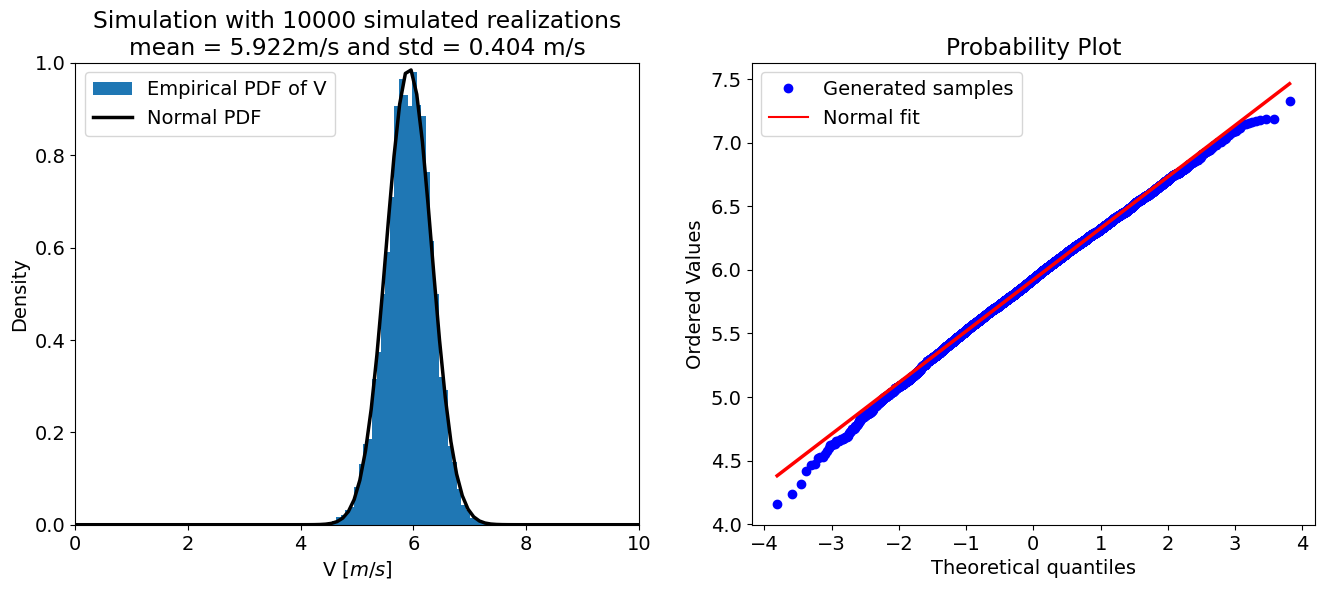
In Part 2 we used a sample of the function of random variables to validate the Taylor approximation (we found that they are generally well-approximated). Now we will assume that the function of random variables has the Normal distribution to validate the moments and see for which range of values they remain a good approximation. This is done by comparing the sample to the assumed distribution; the former is represented by a histogram (also called an empirical probability density function), the latter by a Normal distribution with moments calculated using the Taylor approximation.
We will also use a normal probability plot to assess how well the assumption that \(V\) is normally distributed holds up while varying the value of \(\sigma_R\), introduced next.
Theoretical Quantiles with probplot#
The method probplot is built into scipy.stats (Documentation here) and validates a probability model by comparing samples (i.e., data) to a theoretical distribution (in this case, Normal). The “Theoretical quantile” that is plotted on the x-axis of this plot and measures the distance from the median of a distribution, normalized by the standard deviation, such that \(\mathrm{quantile}=q\cdot\sigma\). For example, \(q=-1.5\) is \(\mu-1.5\cdot\sigma\). The vertical axis is the value of the random variable.
Because we are comparing a theoretical distribution and a sample (data) on the same plot, one of the lines is the Normal PDF, which of course will have an exact match with the theoretical quantiles. This is why the Normal PDF will plot as a straight line in probplot. Comparing the (vertical) distance between the samples and the theoretical distribution (the red line) allows us to validate our model. In particular, it allows us to validate the model for different regions of the distribution. In your interpretation, for example, you should try and identify whether the model is a good fit for the center and/or tails of the distribution.
Note that probplot needs to know what to use for samples (you will tell it this), and what type of theoretical distribution you are using (we already did this for you…norm).
Task 3.1:
Complete the function validate_distribution below (instructions are in the docstring) to plot the empirical probability density function (PDF) of \(V\) using your simulated samples. Also plot the Normal PDF in the same figure using the moments computed from the error propagation law.
Hint: if you are struggling with the code below, re-read the introduction to Part 3 carefully!
def validate_distribution(N, sigma_R, mu_R=0.5, mu_S=0.015, sigma_S=0.002, n=0.013):
"""Generate samples and plots for V
Compares the sampled distribution of V to a Normal distribution defined
by the first moments of the error propagation law.
Comparison is made via two plots:
1. PDF of V~N(mu,sigma) (the approximation) and a histogram (sample)
2. Probability plot, compares quantiles of sample and CDF of V
Only a plot is returned.
MUDE students fill in the missing code (see: ### YOUR CODE HERE ###):
1. Generate samples and find moments
2. Enter data for the histogram
3. Define the moments of the Normal distribution to be plotted
4. Identify the appropriate variables to be printed in the plot titles
5. Enter the data required for the probability plot
"""
V_samples = get_samples(N, sigma_R)
mu_V_samples = V_samples.mean()
sigma_V_samples = V_samples.std()
mu_V_taylor, sigma_V_taylor = moments_of_taylor_approximation(mu_R, mu_S, sigma_R, sigma_S, n)
xmin = 0
xmax = 10
x = np.linspace(xmin, xmax, 100)
fig, ax = plt.subplots(1, 2, figsize = (16, 6))
ax[0].hist(V_samples, bins = 40, density = True,
label = 'Empirical PDF of V')
# **NOTE IN PARTICULAR WHICH mu AND sigma ARE USED!!!**
ax[0].plot(x, norm.pdf(x, mu_V_taylor, sigma_V_taylor), color = 'black',
lw = 2.5, label='Normal PDF')
ax[0].legend()
ax[0].set_xlabel('V [$m/s$]')
ax[0].set_xlim(xmin, xmax)
ax[0].set_ylim(0, 1)
ax[0].set_ylabel('Density')
# **NOTE IN PARTICULAR WHICH mu AND sigma ARE USED!!!**
ax[0].set_title(f'Simulation with {N} simulated realizations'
+ '\n' + f'mean = {round(mu_V_samples, 3)}'
f'm/s and std = {round(sigma_V_samples, 3)} m/s')
# **NOTE IN PARTICULAR WHICH mu AND sigma ARE USED!!!**
probplot(V_samples, dist = norm, fit = True, plot = ax[1])
ax[1].legend(['Generated samples', 'Normal fit'])
ax[1].get_lines()[1].set_linewidth(2.5)
plt.show()
validate_distribution(10000, 0.01)
Validate the Distribution of \(V\) for Various \(\sigma_R\)#
The code below uses a widget to call your function to make the plots and add a slider to change the values of \(\sigma_R\) and visualize the change in the distributions.
Task 3.2:
Run the cell below, then play with the slider to change \(\sigma_R\). How well does the error propagation law match the “true” distribution (the samples)? State your conclusion and explain why. Check also whether there is an impact for different \(\sigma_R\) values.
@interact(sigma_R=(0, 0.1, 0.005))
def samples_slideplot(sigma_R):
validate_distribution(50000, sigma_R);
Task 3.3:
To further validate the error propagation law, estimate the probability that the “true” velocity of the tunnel is in the inaccurate range of values (assuming that the Normal distribution is a suitable model for the distribution of the function of random variables).
Hint: recall that in this notebook a quantile, \(q\), is defined as a standard deviation, and that the probability of observing a random variable \(X\) such that \(P[X\lt q]\) can be found with the CDF of the standard Normal distribution, evaluated in Python using scipy.stats.norm.cdf(q).
Note: As we saw in 3.2, the Normal distribution does not fit the tails of the distribution of the function of random variables perfectly. Although this means using the Normal distribution may not be a good way of estimating the probability of “being in the tails,” the approach in this Task is still suitable for getting an idea of the order of magnitude, and observing how sever this “error” maybe for different assumptions of \(\sigma_R\).
p = 2*norm.cdf(-3)
print(f'The probability is {p:0.6e}')
# extra solution
print(f'The probability is {2*norm.cdf(-2.5):0.6e} for sigma_R = 0.01')
print(f'The probability is {2*norm.cdf(-3.0):0.6e} for sigma_R = 0.05')
print(f'The probability is {2*norm.cdf(-3.5):0.6e} for sigma_R = 0.10')
The probability is 2.699796e-03
The probability is 1.241933e-02 for sigma_R = 0.01
The probability is 2.699796e-03 for sigma_R = 0.05
The probability is 4.652582e-04 for sigma_R = 0.10
Solution 3.2-3.3:
Since the probability plots give the quantiles, we simply need to recall that the probability of being in the “tails” is twice the probability of being less than one of the quantiles (as a negative value); the factor two is due to counting both tails. As we can see, the probability is generally small (no more than about 1%). It is interesting that the probability decreases by factor 100 as the value of \(\sigma_R\) increases from 0.01 to 0.10.
By Lotfi Massarweh and Sandra Verhagen, Delft University of Technology. CC BY 4.0, more info on the Credits page of Workbook.