import matplotlib
if not hasattr(matplotlib.RcParams, "_get"):
matplotlib.RcParams._get = dict.get
3.5. Location, Shape and Scale: Consistent Parameterization#
In the previous sections, you have studied different parametric distributions that can be applied to model the univariate uncertainty in our data. Those distributions were characterized by a set of parameters (e.g.: \(\lambda\) for Exponential distribution), which can be fitted to model real-world data as accurately as possible and, thus, use the distribution for predicting future events. On the distribution summary page), a selection of distribution functions (i.e., the equations for the PDF and CDF) were presented. However, they are just equations! That means that we can reformulate them and parameterize the distribution in a way that best fits our purposes.
In this section the parameterization location, scale and shape will be addressed in the context of scipy Python package (typically abbreviated loc scale and shape). This parameterization is very convenient due to the consistency it provides (all distributions use the same parameters and notation), the ease of the interpretation of those parameters and the advantages of their implementation in computer code. That is why scipy package (between others) uses this parameterization for continuous distribution functions.
Definition of location, scale and shape#
The three parameters serve different roles:
The location parameter (\(\mu\)) shifts the distribution along the x-axis without changing its shape.
The scale parameter (\(\beta\)) determines the width of the distribution.
Finally, the shape parameter (\(\xi\)) is any extra parameter (if any) in the distribution function which is not \(\mu\) or \(\beta\) and describes the form of the distribution.
Let’s see it better with a couple of examples!
You have already been introduced to the (right-tailed) Gumbel distribution, whose PDF is given by
where \(\mu\) is the location parameter and \(\beta>0\) is the scale parameter. You can see that the conventional form of the Gumbel distribution is actually the loc-shape-scale parameterization! We will see more about it later, so let’s focus now on the meaning of those parameters. In the figure below, you can see the PDF of three Gumbel distributions. The blue and the black ones have the same scale parameter but different location. Thus, the distribution moves along x-axis. Note that the location parameter defined the mode of the distribution. The black and red distributions present the same location parameter but different scale. Thus, the mode is located at \(x=0\) in both distributions (since \(\mu\)=0) but the red distribution (with a higher scale) spreads along a wider range of values.

Fig. 3.23 PDF of Gumbel distribution function.#
Since the Gumbel distribution does not present a shape parameter, let’s see it with a different distribution[^density]. The generalized form of Gumbel distribution is the Generalized Extreme Value (GEV) distribution. Similarly to Gumbel distribution (and as you can guess from its name), it is applied to model the probabilistic behavior of extreme observations (you will learn more about this later in the course). The PDF of the GEV is given as
where \(-\infty < \mu < \infty\) is the location parameter, \(\sigma > 0\) is the scale parameter, and \(-\infty < \xi < \infty\) is the shape parameter. Let’s see the effect of the shape parameter!
In the figure below, you can see the PDF (left panel) and the CDF (right panel) of three GEV distributions. They have the same location (\(\mu\)=0) and scale (\(\sigma\)=1) but different shape parameters (\(\xi\) = -1, 0 and 1). You can see that the form of the three distributions is totally different! Don’t worry too much about this specific case, you just need to remember that the shape parameter controls the form of the distribution.

Fig. 3.24 Effect of shape parameter on GEV distribution: (left) PDF, and (right) CDF.#
Standardized form#
In order to address the loc-scale-shape parameterization, we first must define the standardized form of a distribution. The standardized form is one in which there are no extra parameters but shape parameters (if any); the density function is written purely as a function of the random variable \(x\), without any scaling or shifting.
For the right-tailed Gumbel distribution, the standardized form of the PDF would be given by
The standardized Gumbel distribution can be useful when describing some dataset, however, it can be quite limiting for random variables that do not feature this characteristic of mean and variance. Thus, we can shift and scale the standard distribution to give it the characteristics that we want.
From convention to loc-scale-shape parameterization with an example#
As described above, we have to be able to go from the parameters of the conventional form of the distribution (e.g., those on the distribution summary page), to loc-shape-scale in order to use computer packages. Here, we will focus on Python’s scipy library and address the Lognormal distribution, as this distribution is often the one that creates the most confusion. You can find the documentation about the Lognormal distribution in scipy here.
If you follow the documentation link, you will find the following description of the implemented Lognormal distribution:

Fig. 3.25 Screenshot of the Lognormal PDF from scipy stats.#
First, the PDF in standardized form is presented with a shape parameter \(s\). Let’s compare this PDF with the conventional one (from our summary page), which is given by
where \(\mu\) and \(\sigma\) are the mean and standard deviation of the variable’s natural logarithm. If we compare scipy’s parameterization with Equation 1, it becomes clear that the shape parameter \(s\) corresponds to \(\sigma\). That was an easy one!
Let’s focus now on the loc and scale parameters. If we go back to the documentation in the figure, it states that “… lognorm.pdf(x, s, loc, scale) is identically equivalent to lognorm.pdf(y, s) / scale with y = (x - loc) / scale”. Let’s apply this identity and see if we can identify these to parameters.
If we replace the argument with \(y\), then substitute the identity above, we obtain:
If we compare this result with the standardized form of the Lognormal, the parameter \(\operatorname{loc}\) seems absent. Let’s set \(\operatorname{loc} = 0\) and equate it to the standarized form.
which leads to
and thus, \(\ln\left(\operatorname{scale}\right) = \mu\). Therefore, in scipy, we would need to set \(\operatorname{loc} = 0\), \(\operatorname{scale} = e^{\normalsize \mu}\) and \(s = \sigma\) to use the Lognormal distribution.
Let’s verify it using code#
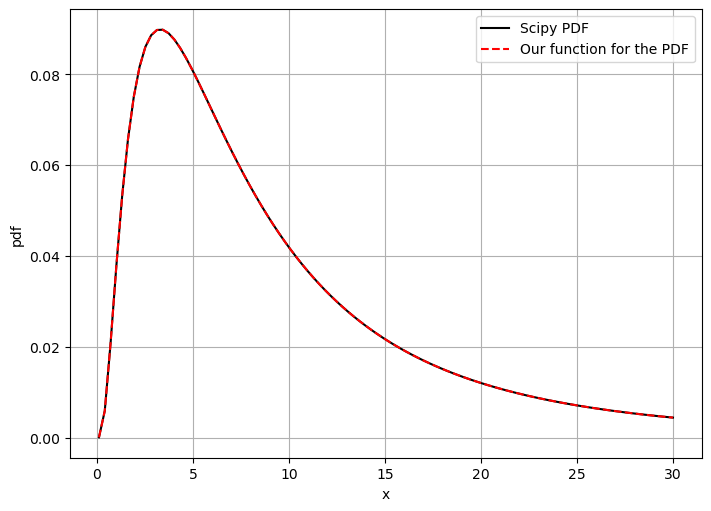
Here, we will define the PDF of the Lognormal distribution using a self-made function and we will compare the results with scipy to check whether we reached to the appropriate solution.
#Import the packages
import numpy as np
from scipy.stats import lognorm
import matplotlib.pyplot as plt
#Create a function for the PDF of the Lognormal distribution
def lognormal_PDF(x, mu, sigma):
density = 1/(x * sigma * (2*np.pi)**0.5)*np.exp(-(np.log(x)-mu)**2/(2*sigma**2))
return density
#Define parameters
mu = 2
sigma = 0.9
# #Transform to loc, scale, shape
loc = 0
shape = sigma
scale = np.exp(mu)
#Define a vector and evaluate the PDF using both the self-made function and scipy
x = np.linspace(0.1, 30, 100)
density_scipy = lognorm.pdf(x, shape, loc, scale)
density_manual = lognormal_PDF(x, mu, sigma)
#Compare by plotting
fig, ax = plt.subplots(1,1, figsize=(7,5), layout='constrained')
ax.plot(x, density_scipy, 'k', label = 'Scipy PDF')
ax.plot(x, density_manual, '--r', label = 'Our function for the PDF')
ax.grid()
ax.legend()
ax.set_xlabel('x')
ax.set_ylabel('pdf');
Attribution
This chapter was written by Patricia Mares Nasarre, Robert Lanzafame, and Max Ramgraber. Find out more here.